Site-to-site VPN beállítása (gyakorlat) 2
Előkészületek
NTP beállítása
Az IKE és az IPSEC protokoll nagyon érzékeny a rendszeridő beállításaira. Mielőtt hozzákezdenél a VPN beállításához, győződj meg róla, hogy a router-ek NTP kliense jól van beállítva, és pontos rajtuk a rendszeridő. A saját országodnak megfelelő nyilvános NTP szervereket például itt is megtalálhatod.
/system clock set time-zone-autodetect=yes time-zone-name=Europe/Budapest
/system ntp client set server-dns-name=0.hu.pool.ntp.org,1.hu.pool.ntp.org primary-ntp=[/resolve 2.hu.pool.ntp.org] secondary-ntp=[/resolve 3.hu.pool.ntp.org]FQDN (teljes host nevek) beállítása
A továbbiakban sok kényelmetlenségtől megkímélheted magadat akkor, ha rendes host neveket hozol létre a peer-ekhez. Ennek különösen akkor lesz jelentősége, ha később nem csak site-to-site, hanem road warrior típusú VPN klienseket is támogatni szeretnél. Ebben a példában az office-hoz az office.myserver.hu, a branch01-hez a branch01.myserver.hu host neveket fogjuk használni.
Ezen felül elvégzünk pár beállítást amivel elérjük, hogy ez a két név a megfelelő IP címekre oldódjon föl.
Az "ISP" internet router-én adjuk meg az IP címeket a host nevekhez, statikus DNS bejegyzések formájában:
/ip dns static
add address=10.3.3.10 name=office.myserver.hu
add address=10.2.2.10 name=branch01.myserver.hu
# Ez már be volt állítva korábban, csak a teljesség kedvéért
/ip dns set allow-remote-requests=yesAz office router-en beállítjuk az "ISP" által adott DNS szervert és a router teljes nevét.
/ip dns set servers=10.3.3.3
/system identity set name=office.myserver.huUgyan ez a branch01 router-en:
/ip dns set servers=10.2.2.2
/system identity set name=branch01.myserver.hu
Mindkettőn teszteld le, hogy működik-e:
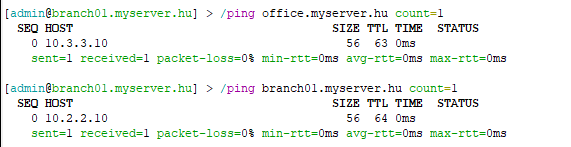
Tanúsítványok generálása
Ahogy korábban jeleztem, tanúsítványokat fogunk használni az azonosításra. Arra készülünk, hogy a fő irodához (office) tovább telephelyeket fogunk csatlakoztatni. Ezért az azonosításhoz szükséges tanúsítványokat és kulcsokat az office router-jén fogjuk előállítani.
Három tanúsítványt fogunk előállítani:
- Certificate Authority
- Központi iroda (
office) branch01
Főbb különbségek:
- A CA lejárati ideje nagyon hosszú. A key-usage részben jó sok dolog szerepel.
- A szervernél a
key-usagerészbentls-serverszerepel. - A kliensnél a
key-usagerészbentls-clientszerepel.
Ha érdekel hogy ezek pontosan mit jelentenek, akkor az X.509 szabványt kell tanulmányoznod. Ennek bemutatása bőven túlmutat egy ilyen egyszerű iromány keretein.
CA tanúsítvány generálása
/certificate add name=ca.myserver.hu country=HU state=Heves locality=Eger organization=myserver.hu common-name=myserver.hu subject-alt-name=DNS:ca.myserver.hu key-size=4096 days-valid=3650 trusted=yes key-usage=digital-signature,key-encipherment,data-encipherment,key-cert-sign,crl-sign
Hozzárendelünk egy privát kulcsot, és aláírjuk saját magával. Ez elég sokáig eltarthat, számításigényes.
/certificate sign ca.myserver.hu
Végül exportáljuk egy állományba. Erre azért van szükség, hogy a másik peer-en importálni tudjuk.
/certificate export-certificate ca.myserver.hu
office peer kulcs és tanúsítvány generálása
/certificate add name=office.myserver.hu country=HU state=Heves locality=Eger organization=myserver.hu common-name=office.myserver.hu subject-alt-name=DNS:office.myserver.hu key-size=4096 days-valid=1095 trusted=yes key-usage=tls-server
Ezt is a CA-val írjuk alá. Eltarthat egy ideig...
/certificate sign office.myserver.hu ca=ca.myserver.hu
Ezt a tanúsítványt nem exportáljuk, mert már azon a router-en van, ahol szükség lesz rá.
branch01 peer kulcs és tanúsítvány generálása
/certificate add name=branch01.myserver.hu country=HU state=Heves locality=Eger organization=myserver.hu common-name=branch01.myserver.hu subject-alt-name=DNS:branch01.myserver.hu key-size=4096 days-valid=1095 trusted=yes key-usage=tls-clientEzt is a CA-val írjuk alá:
/certificate sign branch01.myserver.hu ca=ca.myserver.huA branch01-nél szükséges exportálnunk a tanúsítványt a titkos kulccsal együtt. Erre majd a branch01 router-en lesz szükség.
/certificate export-certificate branch01.myserver.hu type=pkcs12 export-passphrase=abcd1234
Export állományok másolása branch01-re és importálása
A két exportált állományt át kell másolnod a branch01 router-re. A másolást én a példában úgy oldottam meg, hogy WinBox -szal csatlakoztam az office router-hez, és a files menüpont alól letöltöttem őket a saját gépemre. Ezután csatlakoztam a branch01 router-hez is, és ott feltöltöttem őket (szintén WinBox-szal).
Ezután a branch01 router-en így importáltam őket:
/certificate import file-name=cert_export_ca.myserver.hu.crt
/certificate import file-name=cert_export_branch01.myserver.hu.p12Ezután még át kellett írni a neveiket, hogy ne "cert_export" nevűek legyenek. Ennek nincs túl nagy jelentősége. Amikor majd az azonosításhoz meg kell adnod őket, akkor "cert_export_branch01.myserver.hu.p12_0" helyett egyszerűen "branch01.myserver.hu" néven lehet rá hivatkozni. Valahogy így:
[admin@branch01.myserver.hu] /certificate> print detail
Flags: K - private-key, L - crl, C - smart-card-key, A - authority, I - issued, R - revoked, E - expired,
T - trusted
0 A T name="cert_export_ca.myserver.hu.crt_0" issuer=C=HU,ST=Heves,L=Eger,O=myserver.hu,CN=myserver.hu digest-algorithm=sha256 key-type=rsa country="HU" state="Heves" locality="Eger" organization="myserver.hu" common-name="myserver.hu" key-size=4096 subject-alt-name=DNS:ca.myserver.hu days-valid=3650 trusted=yes key-usage=digital-signature,key-encipherment,data-encipherment,key-cert-sign,crl-sign serial-number="4723FDDFBA4C0EE7" fingerprint="d478806e903a39ab9c247fee055913d7b359bf599519edc59ca32ebf10764b3d" invalid-before=dec/29/2020 20:12:56 invalid-after=dec/27/2030 20:12:56 expires-after=521w2d9h51m36s
1 K T name="cert_export_branch01.myserver.hu.p12_0" issuer=C=HU,ST=Heves,L=Eger,O=myserver.hu,CN=myserver.hu digest-algorithm=sha256 key-type=rsa country="HU" state="Heves" locality="Eger" organization="myserver.hu" common-name="branch01.myserver.hu" key-size=4096 subject-alt-name=DNS:branch01.myserver.hu days-valid=1095 trusted=yes key-usage=tls-client serial-number="6E4BF36124495358" fingerprint="623f9943980a8bd320d1b8c250d6061fb8fee8de0c6d924144e5df6f4e1398b4" invalid-before=dec/29/2020 20:18:21 invalid-after=dec/29/2023 20:18:21 expires-after=156w2d9h57m1s
[admin@branch01.myserver.hu] /certificate> set 0 name="ca.myserver.hu"
[admin@branch01.myserver.hu] /certificate> set 1 name="branch01.myserver.hu"
Végül töröltem őket a branch01 router-ről és az office routerről is:
/file remove [find where name=cert_export_ca.myserver.hu.crt]
/file remove [find where name=cert_export_branch01.myserver.hu.p12]
Ezen felül a saját gépemről is.
Figyelem! A fentieket csak a példa kedvéért csináltam ennyire egyszerű módon. A valóságban sokkal erősebb jelszót kellene használnod, és biztonságos módon megoldani az export állományok átmásolását. Sőt ha nagyon szigorúak akarunk lenni, akkor a branch01 privát kulcsát a branch01 router-en kellene előállítanod, és onnan soha nem szabadna kikerülnie. A példa kedvéért (és általános felhasználásra) a fent leírt módszer, a megfelelő elővigyázatosság mellett megfelelő lehet.
Policy template group
A RouterOS bevezetett egy külön entitást a policy -k csoportosítására. Ez a /ip ipsec policy group menüpont alatt található. Az egyedi nevén kívül semmi mást nem kell (és nem is lehet) megadni hozzá. Arra való, hogy a policy-ket és identitásokat csoportosítani lehessen vele. A mi példánkban ennek nincsen túl sok értelme, mert mindkét router-en összesen egyetlen egy identity és egyetlen egy policy-lesz. Ennek a csoportosításnak ott van nagy jelentősége, ahol sok peer és sok policy van.
A példa kedvéért most mégis létrehoznunk policy group-okat.
Az office router-en:
/ip ipsec policy group
add name="branch01.myserver.hu"A branch01 router-en:
/ip ipsec policy group
add name="office.myserver.hu"Phase 1 proposal beállítás (ipsec profile)
Ezt mindkét router-en meg kell tenni. A mi konkrét példánkban előre meghatároztuk azokat a konkrét algoritmusokat, amiket használni fogunk. Ezért itt nem fogunk algoritmus listákat megadni, csak konkrét algoritmusokat. Ezt azért tehetjük meg, mert előre ismerjük az összes peer minden képességét, és tudjuk hogy mit akarunk.
Az IKEv2 első fázisához tartozó algoritmusokat egy külön menüpontban, a /ip ipsec profile alatt kell fölvennünk. Ezt mindkét router-en megtesszük:
/ip ipsec profile
add dh-group=modp2048 enc-algorithm=aes-256 hash-algorithm=sha256 name="myserver.hu" nat-traversal=no proposal-check=strict
Természetesen, ha a Te esetedben valamelyik peer egy NAT-olt hálózaton van, akkor állítsd be a nat-traversal=yes attribútumot. A mi példánkban erre nincs szükség.
Érdekes az elnevezés. Bár ez is egy proposal, de ennek profile a neve. Ennek megvan a maga magyarázata. Elméletileg minden egyes peer -hez külön algoritmus beállításokat lehet megadni. A gyakorlatban azonban ez egyáltalán nem jellemző. A gyakorlatban az összes lehetséges peer-re, vagy legalábbis a peer-ek nagy számosságú csoportjaira azonos algoritmusokat szoktunk használni. Emiatt az algoritmusok beállítása egy külön ipsec profile entitásba került, és névvel van ellátva. A peer-ek létrehozásakor nem a konkrét algoritmus neveket adjuk meg, hanem csak hivatkozunk arra a profile-ra ami meghatározza az algoritmusokat. Ez egyébként azért is jó, mert a profile módosításával egy lépésben át lehet konfigurálni az összes peer-t, ami hozzá van rendelve.
Természetesen nincs annak semmi akadálya, hogy minden egyes peer-hez egy külön profile-t hozz létre, és így peer-enként egyedileg tudd beállítani az algoritmusokat. De ez általában kontraproduktív. A mi konkrét példánkban egyetlen egy peer lesz, de mivel RouterOS-ben a konfigurációnak ilyen a szerkezete, ezért ehhez kell igazodnunk.
A proposal-check=strict beállítással azt írjuk elő, hogy a második fázisban létrehozott SA-k milyen maximális életkorral rendelkezhetnek. (Az első fázisban az életkort is egyeztetjük.) A strict beállítás szigorú, a responder csak akkor fogadja el az initiator által kínált max. életkort, ha az nem nagyobb, mint ami a responder oldalon alapértelmezésként meg van adva.
Phase 2 proposal beállítás (Ipsec proposal)
A második fázishoz külön be kell állítanunk a lehetséges algoritmusokat (amiket korábban tárgyaltunk). Ez RouterOS-ben az /ip ipsec proposal menüpont alatt található.
Ezt mindkét router-en futtatni kell:
/ip ipsec proposal
add auth-algorithms=sha256 enc-algorithms=aes-256-cbc pfs-group=modp2048 name="proposal-myserver.hu" lifetime=30mAz alapértelmezett lejárati idő 30 perc, ezt az igényeknek megfelelően módosítani lehet.
Peer-ek létrehozása
Az office router-en:
/ip ipsec peer
add exchange-mode=ike2 address=10.2.2.10/32 local-address=10.3.3.10 name="peer-branch01" passive=yes send-initial-contact=yes profile="myserver.hu"A branch01 router-en:
/ip ipsec peer
add exchange-mode=ike2 address=10.3.3.10/32 local-address=10.2.2.10 name="peer-office" passive=no send-initial-contact=yes profile="myserver.hu"
Érdekességek:
- Az
addressattribútum nem csak konkrét cím lehet, hanem címtartomány is. Ha egy policy-nak több peer címe is megfelel, akkor a RouterOS azt választja közülük, amelyik a legspecifikusabb. - A
local-addressazt a címet adja meg, amelyiken az IKE démon várja a bejövő kapcsolatokat. (Ezt nem kötelező megadni, ha nem adod meg, akkor a peer bármely címre beérkező kulcs-csere kéréshez használható.) - A
passiveazt jelenti, hogy az IKE démon másik oldalon levő peer-re vár a kapcsolat felépüléséhez. Ha a passzív mód ki van kapcsolva, akkor a peer megpróbálja automatikusan végrehajtani nem csak az első fázist, hanem a másodikat is (feltéve hogy az első fázis után vannak létrehozva a peer-nek megfelelő policy-k). RouterOS-ben mindkét oldal lehet initator és responder is. - A
send-initial-contactbeállítás hatására a egy "initial contact" csomagot küld a peer-nek. Ennek hatására a (távoli) peer kitörli az összes korábban létrehozott SA-t, ami a helyi peer forráscíméhez tartozik.
Bővebb leírás itt: https://wiki.mikrotik.com/wiki/Manual:IP/IPsec#Peers
Identity hozzáadása
Ahogy korábban írtuk, ez szolgál a peer-ek kölcsönös azonosítására. Az azonosítást a korábban létrehozott kulcsokkal és tanúsítványokkal valósítjuk meg.
Az office router-en:
/ip ipsec identity
add auth-method=digital-signature certificate=office.myserver.hu match-by=certificate my-id=fqdn:office.myserver.hu peer=peer-branch01 remote-certificate=branch01.myserver.hu remote-id=fqdn:branch01.myserver.hu policy-template-group=branch01.myserver.hu
A branch01 router-en:
/ip ipsec identity
add auth-method=digital-signature certificate=branch01.myserver.hu mode-config=modeconf-branch01 my-id=fqdn:branch01.myserver.hu peer=peer-office remote-id=fqdn:office.myserver.hu policy-template-group=office.myserver.hu
Egy kis magyarázat hozzá:
- Az office router esetében megvan mindkét certificate. Az office.myserver.hu és a branch01.myserver.hu nevű is. Mivel a branch01 tanúsítványait a jövőben is az office router-en kívánjuk kiállítani, ezért ez a jövőben is mindig rendelkezésre fog állni. Emiatt az azonosításnál a
match-by=certificateértéket adtuk meg. Ez azt jelenti, hogy az azonosítást a teljes certificate pontos egyezése alapján végzi el. Ha ezt megadod, akkor persze kötelező megadni aremote-certificateértékét is (tudnia kell, hogy a távoli peer tanúsítványát mivel hasonlítsa össze). - A branch01 router esetében nem rendelkezünk az office tanúsítványával. Bár elméletileg ezt az office routeren kiexportálhattuk volna (privát kulcs nélkül!), és a branch01 router-en importálhattuk volna. Ebben az esetben ott is használhatnánk a
match-by=certificatebeállítást. De ha így tennénk, akkor ez azt jelentené, hogy minden alkalommal amikor az office gép tanúsítványa lejár, azt újra kellene exportálni és újra föl kellene másolni a branch01 routerre is. Ez ebben a példában nem tűnik problémásnak. De képzeljük el azt a helyzetet, amikor az office router-hez már 20 különböző branch-et csatlakoztattunk. Könnyen abban a helyzetben találhatjuk magunkat, hogy a VPN responder tanúsítványának megújítása után 20 különböző gépre kell fölmásolni és beállítani az új tanúsítványt. Ez elég kényelmetlen lenne. Ehelyett használhatjuk amatch-by=remote-idés aremote-id=fqdn:beállítást. Ez a beállítás a következőt teszi:- Először természetesen (mint mindig) ellenőrzi a távoli peer tanúsítványának digitális aláírását és lejárati idejét. Itt használjuk ki a PKI nyújtotta előnyt: ellenőrizni tudjuk a távoli peer megbízhatóságát egy harmadik fél (a CA) segítségével. (Bár a mi példánkban a CA -t is mi valósítjuk meg, de a CA cert lejárata 10 év.)
- Ha ezt rendben találja, akkor a
common-namemezőjében megkeresi, hogy milyenfqdn-re szól a tanúsítvány - Ezt hasonlítja össze a
remote-id:fqdn:mezőben megadott fqdn értékkel.
Az egyeztetést sok más módon el lehet végezni. Ezeket nem sorolom föl itt, mert a mi példánkhoz nem szükségesek, és tényleg nagyon sok lehetőség van. Bővebb leírást itt találsz: https://wiki.mikrotik.com/wiki/Manual:IP/IPsec#Identities
IKE működésének ellenőrzése (első fázis)
Ezen a ponton a két router IKE démonjainak tudni kell azonosítani egymást, és SA-kat készíteni.
Ha megnézed a naplót (/log print) akkor az office oldalon valami ilyesmit kell látnod:
10:58:30 ipsec,info new ike2 SA (R): 10.3.3.10[4500]-10.2.2.10[4500] spi:7d0560af36a26da3:4caa053a4ee2453e
10:58:30 ipsec,info,account peer authorized: 10.3.3.10[4500]-10.2.2.10[4500] spi:7d0560af36a26da3:4caa053a4ee2453e
10:58:30 ipsec,error no policy found/generated A branch01 oldalon pedig ilyet:
10:58:31 ipsec,info new ike2 SA (I): 10.2.2.10[4500]-10.3.3.10[4500] spi:4caa053a4ee2453e:7d0560af36a26da3
10:58:31 ipsec,info,account peer authorized: 10.2.2.10[4500]-10.3.3.10[4500] spi:4caa053a4ee2453e:7d0560af36a26da3Ha nem ezt látod, akkor ne menj tovább. Nincs értelme további dolgokat beállítani addig, amíg ez nem működik.
Policy-k létrehozása manuálisan
A responder oldalon a napló utolsó sorában látható egy hibaüzenet: no policy found/generated. Ez azért számít hibának, mert policy megadása nélkül az IKE démon csak az első fázist tudja befejezni. A második fázishoz azért szükséges a policy-k megadása, mert az IKE démon minden policy-hoz külön SA-t generál. Mivel mi az identity -nél mindkét router-nél a generate-policy=no beállítást adtuk meg, ezért a rendszer nem generál dinamikusan policy-ket. Helyette csak azokat tudja használni, amiket előre (kézzel) fölvettünk. De mivel ilyeneket még nem vettünk föl, ezért nincsen egyetlen egy policy se, amihez a második fázis lefuttatásával SA-t tudna generálni. Így tehát egyetlen egy SA se jön létre. Ez pedig nyilvánvalóan hiba (hiszen SA-k hiányában semmiféle IPSEC kommunikáció nem lehetséges).
Az office oldalon a következő policy-t vesszük föl:
/ip ipsec policy
add dst-address=172.16.1.0/24 peer=peer-branch01 proposal=proposal-myserver.hu src-address=172.16.2.0/24 tunnel=yes group=branch01.myserver.hu
A branch01 oldalon ennek a párját:
/ip ipsec policy
add dst-address=172.16.2.0/24 peer=peer-office proposal=proposal-myserver.hu src-address=172.16.1.0/24 tunnel=yes group=office.myserver.hu
Egy kis magyarázat a beállításokhoz:
- Az
src-addressés adst-addressmondja meg azt, hogy milyen csomagokat szeretnénk enkapszulálni. Ez az eredeti csomag forrás- és célcímére vonatkozó feltétel. Itt nem csak konkrét címeket, hanem címtartományokat is meg lehet adni. - Lehetne megadni feltételt
src-portésdst-port-ra is, illetveprotocol-ra (tcp, udp) is. Ezt mi most nem tesszük meg, mert a két telephely közötti kapcsolatot nem szeretnénk korlátozni. De jó ha tudod: a megfelelő policy-k és feltételek megadásával el tudod érni például azt, a titkosítást szelektíven, csak bizonyos szolgáltatásokhoz tartozó adatforgalomra korlátozd. - A
peermondja meg, hogy melyik peer felé kell küldeni az enkapszuláció után létrejött új IPSEC csomagot. - A
tunnel=yesbeállítással írjuk elő az alagút módot. - A
groupbeállítás arra jó, hogy a policy-t hozzárendeljük a megadott csoporthoz. Ennek akkor van igazán értelme, ha a peer a kapcsolódáskor nagyon sok policy-t generál dinamikusan. Mi csak azért vettük föl ide hogy ezen keresztül be tudjuk mutatni a használat módját.
Ha beírod hogy /ip ipsec policy export akkor azt fogod látni, hogy az exportba beleírja az sa-src-address és sa-dst-address attribútomokat is.

Ezek valójában ready-only attribútumok, és a policy-hez rendelt peer alapján automatikusan vannak meghatározva. Az egy RouterOS bug, hogy ezt is beleteszi az exportba. Amikor a policy-k módosításán dolgozol, akkor ez ne tévesszen meg.
IKE működésének ellenőrzése (második fázis)
A fenti két policy létrehozása után ezeknél a policy-knél meg kell hogy jelenjen az A flag, ami azt jelzi hogy aktív.
Az office router-en:
[admin@office.myserver.hu] /ip ipsec policy> print detail
Flags: T - template, X - disabled, D - dynamic, I - invalid, A - active, * - default
0 T * group=default src-address=::/0 dst-address=::/0 protocol=all proposal=default template=yes
1 A peer=peer-branch01 tunnel=yes src-address=172.16.2.0/24 src-port=any dst-address=172.16.1.0/24 dst-port=any protocol=all action=encrypt level=require ipsec-protocols=esp sa-src-address=10.3.3.10 sa-dst-address=10.2.2.10 proposal=proposal-myserver.hu ph2-count=1
[admin@office.myserver.hu] /ip ipsec policy>
A branch01 router-en:
[admin@branch01.myserver.hu] /ip ipsec policy> print detail
Flags: T - template, X - disabled, D - dynamic, I - invalid, A - active, * - default
0 T * group=default src-address=::/0 dst-address=::/0 protocol=all proposal=default template=yes
1 A peer=peer-office tunnel=yes src-address=172.16.1.0/24 src-port=any dst-address=172.16.2.0/24 dst-port=any protocol=all action=encrypt level=require ipsec-protocols=esp sa-src-address=10.2.2.10 sa-dst-address=10.3.3.10 proposal=proposal-myserver.hu ph2-count=1
[admin@branch01.myserver.hu] /ip ipsec policy>
A default nevű nullás policy template mindkét oldalon megjelenik, ezzel most nem kell foglalkozni.
Ezen felül, a /ip ipsec installed-sa menüpont alatt meg tudod nézni az IKE második fázisában generált SA-kat. Ez az office router-en például valahogy így néz ki:
[admin@office.myserver.hu] /ip ipsec installed-sa> print
Flags: H - hw-aead, A - AH, E - ESP
0 E spi=0x798ACAD src-address=10.2.2.10 dst-address=10.3.3.10 state=mature auth-algorithm=sha256 enc-algorithm=aes-cbc enc-key-size=256 auth-key="c2c879d6e7db7221df2ddb3e14b139e7a614ea54a85cabbe672cc0f8a6942d67" enc-key="3f87e644e9d5085bb2f19c55cb111f4662ab4140187d898d6eddedd5989211b6" add-lifetime=24m6s/30m8s replay=128
1 E spi=0x40A1E9 src-address=10.3.3.10 dst-address=10.2.2.10 state=mature auth-algorithm=sha256 enc-algorithm=aes-cbc enc-key-size=256 auth-key="72819bd20e06f814859e44bd35e47b848e05c9230ca0d0006e56962bf89e71e5" enc-key="6900d551d05d522263402c7231e7de154c3c08d58bca850d9aa31f75cbf5f333" add-lifetime=24m6s/30m8s replay=128
[admin@office.myserver.hu] /ip ipsec installed-sa>
Itt látható, hogy a két peer között két SA jött létre (a küldésre és a fogadásra). Ezen felül látszódnak a választott algoritmusok, a titkosító kulcsok, és az életkor.
Ha megfelelő hardvert és megfelelő algoritmus beállításokat használtál, akkor itt az E betű mellett megjelenik egy H betű is. Ez jelzi azt, hogy az SA-hoz elérhető a hardveres gyorsítás. A mi példánkban ez azért nincs kiírva, mert a teszt során egy virtuális gépen futtattam egy demo router-t, és abban nincsen ilyen támogatás.
Hiányzó NAT bypass szabályok
Ha ezek után megpróbáljuk mondjuk az office telephelyen levő PC2 gépről elérni a branch01 gépen levő PC1 gépet, akkor a következőt fogjuk látni:

Ez elsőre érthetetlennek tűnhet. Az az ICMP csomag ami a 172.16.2.10 gépről indult el a 172.16.1.10 irányába, elvileg illeszkedik az általunk létrehozott policy-ra, és becsomagolás után az alagúton kellene hogy átmenjen. De láthatóan nem ez történik. Helyette az office router ezt a csomagot továbbküldte az "internet" irányába, és az "ISP" fő routere (10.3.3.3) azt a választ küldte rá, hogy ezt erre a privát címre ő nem tud útvonalat választani. Ha az ICMP hiba a 10.3.3.3 -tól jött vissza akkor a csomag egyértelműen kiment az internetre, méghozzá titkosítatlanul.
Mi történik itt? A magyarázathoz ismét a packet flow diagramhoz kell visszatérnünk.
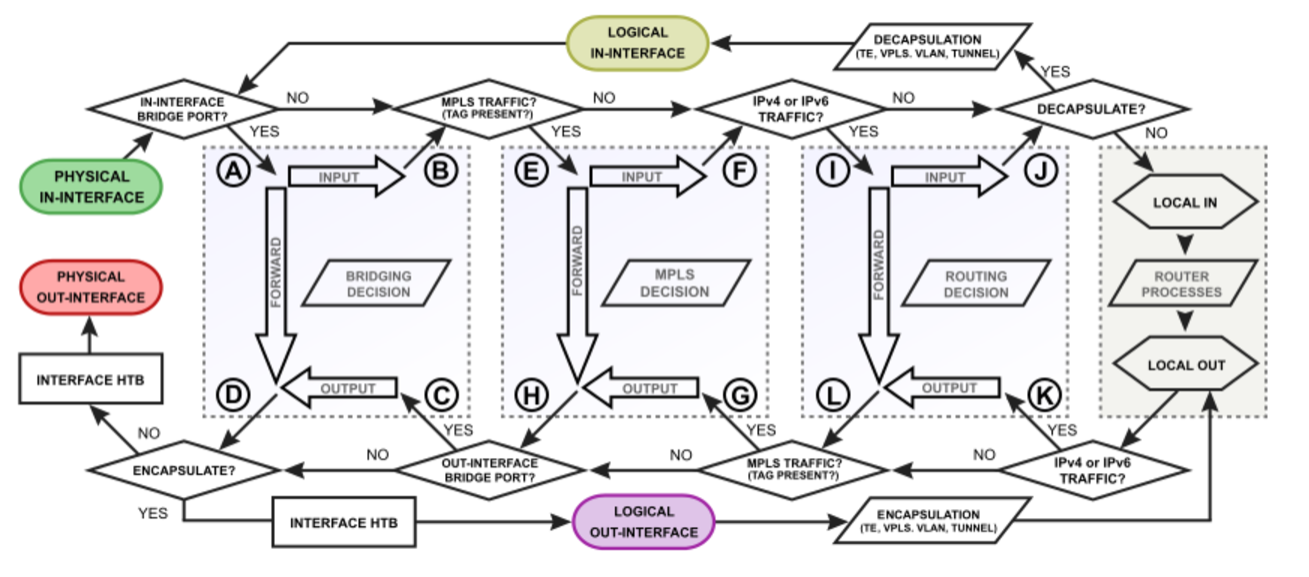
Ahogy korábban írtuk, a csomagok enkapszulációja (a policy szabályok futtatása) az egyik legutolsó lépés. A switching és a routing jóval hamarabb fut le, mint az enkapszuláció. Az office router tűzfalában be volt állítva egy ilyen NAT szabály:
/ip firewall nat
add action=masquerade chain=srcnat out-interface=ether1-internetEz a címfordítás szükséges ahhoz, hogy az office és branch01-en belül található, privát címmel rendelkező gépek el tudják érni az interneten található nyilvános szolgáltatásokat. De mi történik akkor, amikor nem az internetet, hanem a másik privát LAN-on belül található címet akarjuk elérni? Az az ICMP ping csomag aminek a forráscíme 172.16.2.10 és a célcíme 172.16.1.10, illeszkedik erre a NAT szabályra. Ez azért van, mert az illeszkedés egyetlen feltétele az, hogy a kimenő interface az ether1-internet interface legyen.
Hogy pontosan miért illeszkedik, azt alább még bővebben kifejtem. A layer 3 routing akkor kezdődik el, amikor a csomag áthalad a fenti ábrán az I vagy K betűvel jelölt csomópontok valamelyikén. Ez belül így néz ki:
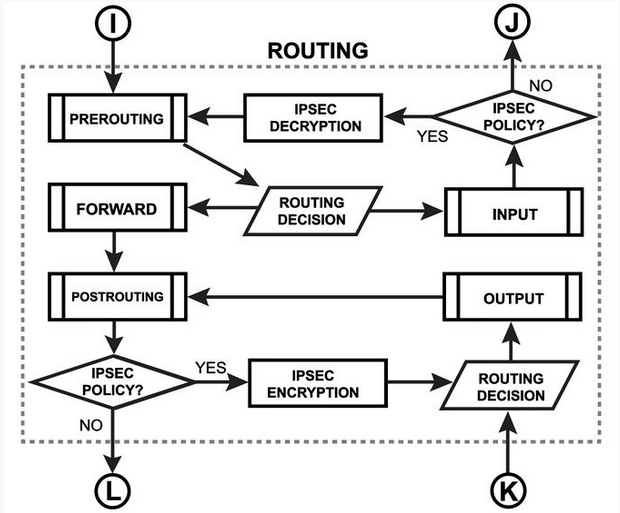
A layer 3 routing során a routing decision doboz az a művelet, ahol a router az útvonalválasztást elvégzi. Ezen a ponton már eldőlt hogy mi a csomag célcíme. Ekkor a RouterOS átnézi az éppen aktuális routing táblázatot. Választ egy route-ot, amin keresztül a célcím elérhető. Így dönti el, hogy a távozó csomag melyik interface-re lesz kiírva. A dst-nat feldolgozása a prerouting részben van. (Logikus, hogy a célcím módosítása megelőzi az útvonal választását.) Az src-nat (forrás cím módosítása) a postrouting-ban van. A fenti layer 3 routing diagramban szereplő alprocesszek részletesebb kibontása alább látható.
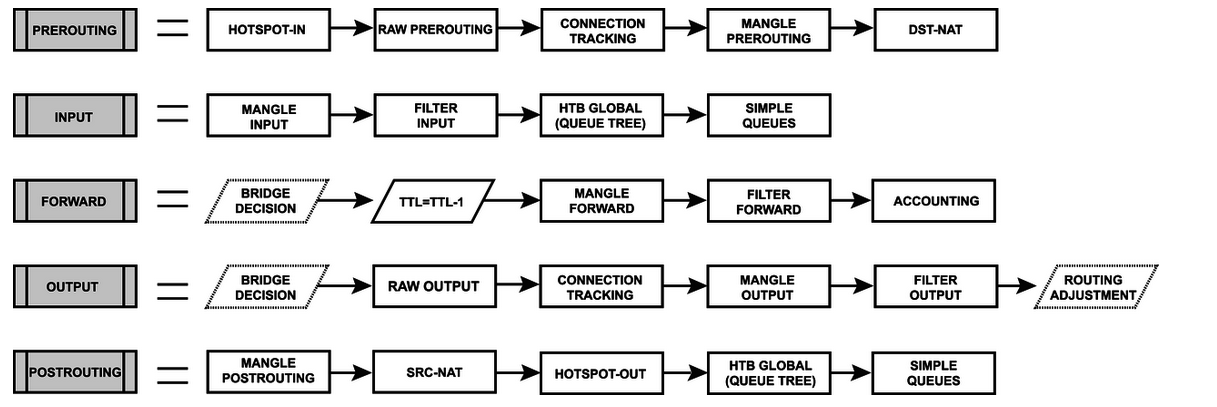
Az IPSec policy-k jóval az útvonalválasztás után futnak le. A mi példánkban a 172.16.1.0/24 célcímhez keresünk útvonalat. Az office router saját routing táblázatában a 172.16.1.0/24 alhálózathoz nincsen megadva külön route. A layer 3 routing szempontjából nézve az a megfelelő route amin keresztül ez a célcím elérhető, a default gateway. Ehhez az ether1-internet interface tartozik. Ez egy WAN interface! A masquerade NAT szabály pedig erre illeszkedik:
/ip firewall nat
add action=masquerade chain=srcnat out-interface=ether1-internetMivel ez a NAT szabály illeszkedik, ezért a router lecseréli a forráscímét arra a címre, ami az ether1-internet interface-en van. Mire a csomag eléri az IPSEC policy-kat, addigra a forráscíme 10.3.3.10 lett. Erre nem illeszkedik egyik policy sem, ezért akadály nélkül távozik az ether1-internet interface-en. Beérkezik az ISP routeréhez, és ez egyből ICMP hibát küld vissza (nincs hozzá útvonal).
Ezt azért magyaráztam el ennyire részletesen, hogy belássuk: a probléma nem csak annyi, hogy a csomag nem jut el a céljához. A csomag távozik az internet irányába, ráadásul titkosítatlanul! Ez TCP kapcsolatok esetén még talán nem túl nagy probléma, mert ott csak TCP SYN csomagok tudnak kimenni (a kapcsolat nem épül föl). De UDP csomagok esetében ez azt jelenti, hogy a rosszul beállított routing és NAT szabályok miatt pont az ellenkezőjét értük el annak, amit akartunk: önként küldjük a potenciálisan bizalmas adatokat a nagyközönség felé. Ahogy azt később látni fogjuk, ez a probléma fokozottan jelentkezhet azokban az esetekben, amikor a VPN (kliens) oldalon nem kézzel fölvett, statikus policy-kat használunk, hanem egy template-ből generáljuk őket. Ha egy hiba miatt a VPN kapcsolat nem épül föl, akkor a dinamikus policy-k nem jönnek létre, és ennek hatására az internet irányába titkosítatlan csomagok hagyhatják el a csomópontot. Ezt esetleg nehezebb lehet észrevenni, mert csak VPN kapcsolat hiba esetén jelenik meg.
Azt a jelenséget, melynek során a router a hiányzó vagy hibás beállításából fakadóan rossz helyre küldi a csomagokat, szokás úgy nevezni hogy package leaking.
Ezen problémák megszüntetéséhez két dolgot kell tennünk.
NAT bypass
Az egyik megoldás az, hogy úgy módosítjuk az src-nat szabályokat, hogy ezeknek a csomagoknak a forrás címét nem írjuk át. Ezt persze mindkét telephelyen meg kell tenni ahhoz, hogy oda- és vissza is illeszkedjenek az ipsec policy-k.
Például az office route-en ezt megtehetjük így:
/ip firewall nat
add chain=srcnat src-address=172.16.2.0/24 dst-address=172.16.1.0/24 action=accept place-before=0
Ennek az eredménye egy ilyen NAT táblázat:
[admin@office.myserver.hu] /ip firewall nat> print detail
Flags: X - disabled, I - invalid, D - dynamic
0 chain=srcnat action=accept src-address=172.16.2.0/24 dst-address=172.16.1.0/24
1 chain=srcnat action=masquerade out-interface=ether1-internet Azok a csomagok amikre később illeszkedik az ipsec policy, illeszkednek a legelső NAT szabályra is. Mivel ott action=accept van, ezért ezekre a csomagokra a NAT feldolgozás befejeződik, a második action=masquerade szabály sosem fut le rájuk.
Ha ezt így próbáljuk meg kezelni, akkor előre ismernünk kell, hogy milyen cél alhálózatok esetében nem akarunk masqurade/srcnat címfordítást végezni. (A mi site-to-site példánkban ez a helyzet.)
Ha sok ilyen cél alhálózat van, akkor az összes ilyen szabály felsorolása és a policy-kkal való szinkronban tartása fáradságos munka lehet, ráadásul könnyű hibázni. Ha az összes IPSEC policy-re illeszkedő csomagnál el akarjuk kerülni a címfordítást, akkor egyszerűbb ha egy plusz feltételt adunk hozzá, az alábbi módon:
VPN Bypass blackhole route hozzáadásával
A másik megoldás az, hogy elhelyezünk olyan route-okat a routing táblázatban, amik az ilyen célcímekre megnő csomagokat egy helyi bridge felé irányítják. Például az office router-en:
/interface bridge
add name=vpn-blackhole
/ip route
add dst-address=172.16.1.0/24 distance=1 gateway=vpn-blackhole comment="bypass NAT for branch01"Az fontos, hogy a distance értéke a alacsonyabb legyen, mint bármilyen WAN -hoz tartozó route distance értéke. Ezzel lehet garantálni azt, hogy ezek a csomagok sosem hagyják el a router-t a WAN irányába. Itt mi egy külön erre a célra dedikált, port nélküli hidat hoztunk létre. Elméletileg ehelyett megadhatnánk bármelyik másik helyi interface-t is. Mivel az ipsec policy a csomag kiküldése előtt lefut és "elhasználja" a csomagot, ezért ez a route a valóságban sosem lesz használva arra, hogy a csomag kiküldésre kerüljön. Csak annyi a célja, hogy megakadályozza az src-nat és masquerade NAT szabályok lefutását. A biztonság kedvéért azonban mégis érdemes létrehozni egy port nélküli hidat, mert így ezek a csomagok nem fognak távozni egyetlen porton sem (nem csak a WAN portokon, hanem semmilyen porton).
Ha nem csak statikus policy-ket használunk hanem dinamikusan, template-ből generált policy-kat is, akkor ezek csak az SA-k létrehozása után jönnek létre automatikusan. Ha valamilyen hiba (például a távoli peer elérhetetlensége) miatt nem sikerül a kulcs csere, akkor nem jönnek létre policy-k, és azok a csomagok amik normál esetben enkapszulációra kerülnének, normál módon kerülnek továbbításra. A dinamikusan generált policy-k esetében általában nem lehet előre tudni azt, hogy milyen célcím tartományokra kell NAT bypass-t alkalmazni.
Ha tényleg minden hibalehetőséget ki szeretnél zárni, akkor létrehozhatsz ilyen route-okat az összes RFC 1918 prefixhez.
/interface bridge
add name=vpn-blackhole
/ip route
add dst-address=10.0.0.0/8 gateway=vpn-blackhole distance=1 comment="Blackhole for RCF 1918 class A"
add dst-address=172.16.0.0/12 gateway=vpn-blackhole distance=1 comment="Blackhole for RCF 1918 class B"
add dst-address=192.168.0.0/16 gateway=vpn-blackhole distance=1 comment="Blackhole for RCF 1918 class C"
A distance beállításról:
- A helyi hidakhoz automatikusan létrehozott route-ok távolsága mindig nulla. A fenti route-ok ennél magasabb költségűek, ezért nem akadályozzák a helyi LAN-ok adatforgalmát.
- Az
ipsec policy-k által enkapszulált csomagok soha nem érik el a fizikai interface-eket, ezért a fenti három route ezeknél a csomagoknál soha nem lesz arra használva, hogy fizikai interface-re küldje ki őket. - A fenti szabályoknál olyan
distanceértéket adj meg, ami a WAN irányába menő route-oknál alacsonyabb. Ha dhcp klienst használsz az internethez csatlakozáshoz, akkor állítsd át a/ip dhcp-clientalatt adefault-route-distanceértékét magasabbra, mondjuk 10-re.
Ez a fenti módszer általában jobb, mint a kézi NAT bypass szabályok hozzáadása. Az egyik előnye, hogy automatikusan működik az összes jövőben csatlakozó policy-ra. A másik előnye, hogy a fenti három szabály garantáltan "megfogja" az összes olyan csomagot, amiknek az enkapszulációját a router egy konfiurációs (vagy policy generálással kapcsolatos) hiba miatt elmulasztja.
Figyelem! Ha a routing táblázatokhoz BGP vagy OSFP protokollt használsz, akkor az egész VPN alagutat máshogy kell kialakítani. Ebben a cikkben ezzel nem foglalkozom (de ha ilyeneket használsz akkor valószínűleg érted hogy miről van szó.)
Tesztelés NAT bypass beállítása után
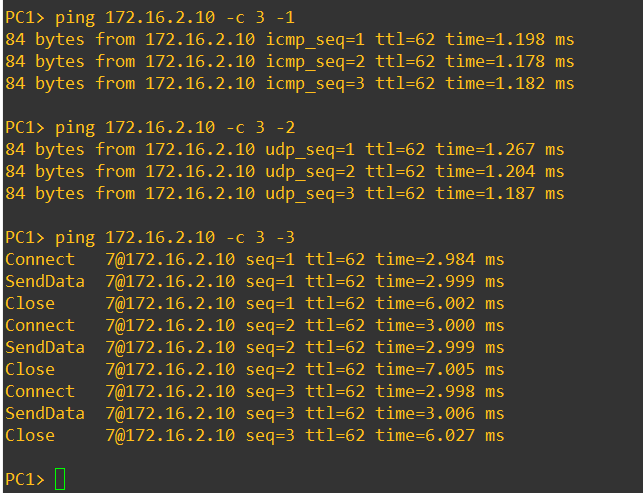
Ezek után a PC2-ről el lehet érni a PC1-et, ICMP UDP és TCP protokollal is:
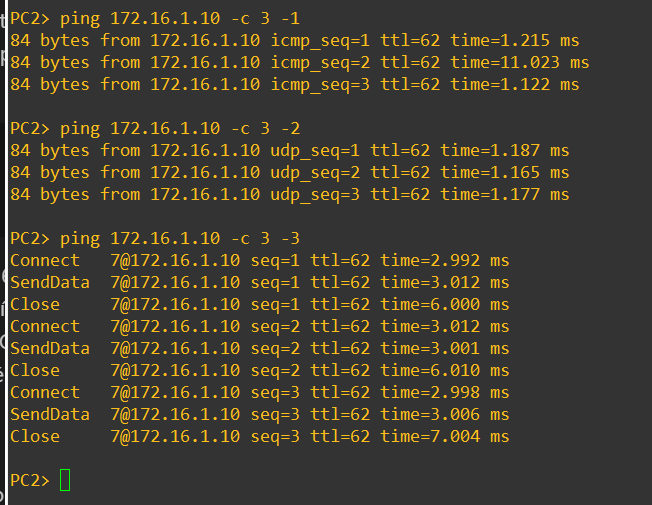
Illetve a másik irányban a PC1-ről a PC2-őt:
Ha traceroute-ot futtatunk rá ICMP protokollal akkor az látszódik, hogy összesen 3 hop távolságra van a cél:
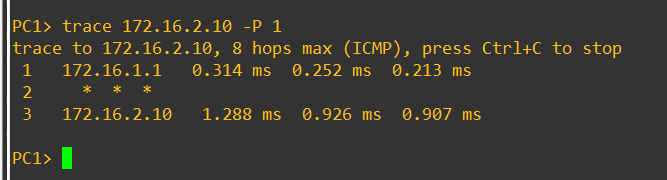
A második hop címe azért nem látszódik, mert a VPN alagúton való átjutáshoz az enkapszuláció után a RouterOS egy "logical out-interface" nevű logikai (belső) interface-t használ. Ez látszódik a packet flow ábrán is. Ez a belső interface nem érhető el a RouterOS /interface menüjéből. Nincsen neve és nincsen címe sem. Bár az igaz, hogy amikor ezt az interface-t eléri az ICMP ping csomag, akkor csökkentjük a TTL értékét, és ha nullára csökkent akkor eldobjuk a csomagot. Azonban a RouterOS nem küld vissza "ICMP Time Exceeded" üzenetet, mivel ehhez szükség lennne a forráscím megadására. Tehát a VPN alagúton való áthaladás csökkenti a TTL értékét, de az ICMP alapú traceroute-ban nem látszódik ennek az állomásnak a címe, mert az a belső interface ami a TTL-t csökkenti az alagúton való áthaladáskor, nem rendelkezik olyan forrás címmel, amit föl lehetne használni az ICMP válasz visszaküldésére.
A traceroute-ban így csak annyit látunk, hogy interneten való (potenciálisan sok router-en keresztüli) áthaladás helyett az alagút egyetlen (ismeretlen című) hop-ként látszódik.
MTU és fragmentáció
Amikor az eredeti IP csomagokat IPSEC csomagokba enkapszuláljuk, akkor természetesen az IPSEC csomagok mérete nagyobb lesz, mint az eredeti IP csomagok mérete. Hogy pontosan mennyivel nagyobb, azt ismét Nikita Tarikin előadásáról származó ábrával mutatom be. Az alábbi ábra egy rendes IP csomag illetve egy IPSec ESP csomag felépítését mutatja (tunnel módban):

Ha a tunnel módon felül még NAT-T beállítást is használunk, akkor további 8 byte-ot elvesz az IP fejléc és az IPSEC adat blokk közé beszúrt extra UDP fejléc:

Ethernet (layer 2) szinten a maximális csomagméret általában 1500 byte. Egy normál IPv4 csomag esetében az IPv4 header 20 byte-ot foglal el. (Ebben van verziószám, TTL érték, al-protokol száma, forrás- és célcím stb. Részletek itt találhatók. Emiatt egy ethernet-en keresztül küldött normál IP csomagban a hasznos adat (payload) mérete legfeljebb 1492 byte lehet.
Ha megnézzük az alagút módban használt IPSEC/ESP csomagot akkor azt látjuk, hogy az eredeti (teljes) beágyazott és titkosított IP csomagon felül még el kell tárolnunk az ESP fejlécet, az ESP tail-t (amiben pl. a csomag integritását biztosító ellenőrző összeg szerepel). Ezen felül egy új IP header is bekerül az elejére (amiben az sa-src-address és az sa-dst-address közötti forgalmazáshoz szükséges). Ha pedig még NAT-T módot is használunk, akkor még újabb 8 byte-ot föl kell használunk.
Ha az eredeti ethernet csomag mérete 1500 byte volt, és az IPSEC/ESP csomag (ethernet) mérete is legfeljebb 1500 byte lehet, akkor az enkapszulációt természetesen nem lehet elvégezni. Egyszerűen azért, mert az eredeti csomag nem fér bele a legnagyobb méretű IPSEC csomagba sem. IPv6 esetében még rosszabb a helyzet, az IPv6 header mérete ugyanis 40 byte.
Amikor a router ilyen feladattal szembesül, akkor az eredeti IP csomagot töredékekre bontja (idegen szóval fragmentálja), és ezeket a töredékeket külön IPSEC csomagokban továbbítja. A távoli peer ezeket a töredékeket fogadja, egyesével kicsomagolja, és ezekből állítja elő az eredeti csomagot. A távoli peer addig nem tudja helyreállítani az eredeti csomagot, amíg az összes töredék meg nem érkezik. Ezért tárolnia kell őket egy ideig. Előfordulhat, hogy nem érkezik meg minden töredék. (Az IPSEC csomagok datagram típusúak, nincs arra garancia hogy megérkeznek.) Ilyenkor a távoli peer eldobja a használhatatlan töredékeket. De ezt csak egy idő után teszi meg, és addig is fölöslegesen tárolja őket. A fragmentálás jelentősen rontja a továbbított és a hasznos adatmennyiség arányát. A helyzet tovább romlik akkor, ha egy adott útvonalon több helyen kell fragmentálni. A többszörös fragmentáció hatására a kapcsolat átviteli sebessége jelentősen csökkenhet, a válaszidők jelentősen növekedhetnek, és az átvitelben résztvevő eszközök terhelése növekedik. Többszörös fragmentáció előfordulhat például akkor, ha az útvonalon van egy PPPoE alagút, vagy ha egy nem optimális router az IPSEC csomagokat újabb IPSEC csomagokba enkapszulálja stb.
MTU Path Discovery
A fenti okokból a fragmentációt lehetőség szerint el kell kerülni! Ebből a célból használják a Path MTU Discovery (rövidítve MTUPD) nevű eljárást. Ez máshogy működik IPv4 és IPv6 esetén. Azonban mindkettőre igaz, hogy kizárólag kapcsolatállapot alapú protokollokkal működik. Az ilyen protokollok a kommunikációt úgy végzik el, hogy először kiépítenek egy utat (path), és az adatokat ezen az úton át küldik el egymásnak. A csomagkapcsolt (datagram) protokollok esetén az MTU Path discovery nem működik.
- IPv4 esetében úgy működik az MTUPD, hogy a kiküldött IP csomagnál a küldő fél beállítja a
DF(don't fragment) bitet. Bármely eszköz ami egy ilyen csomagot nem tud fragmentálás nélkül továbbítani, eldobja a csomagot és visszaküld egy "Fragmentation eeded" ICMP csomagot a feladónak. Ebben az üzenetben szerepel az elérhető legnagyobb MTU is. A küldő fél ezzel az új MTU-val próbálja újra a csomag küldését. Ez a folyamat addig ismétlődik, amíg a csomag el nem jut (fragmentálás nélkül) a célcímhez. - Az IPv6 router-ek nem támogatják a fragmentálást, és az IPv6 fejlécben nincsen
DFbit. Az IPv6 protokoll esetében az MTU Path discovery úgy működik, hogy eredetileg azt feltételezzük, hogy az útvonal MTU-ja ugyan az, mint a link MTU-ja. (A link MTU-ját az a helyi interface adja meg, amin keresztül a küldő fél kiküldi a csomagot.) Ezután az IPv4 protokollhoz hasonlóan, bármely eszköz ami a túl nagy méret miatt nem tudja továbbítani a csomagot, visszaküld egy ICMPv6 "túl nagy csomag" üzenetet a feladónak. - Ha egy korábban kialakított kapcsolatban csökken az MTU értéke, akkor az első túl nagy csomag ICMP hibát okoz, és a küldő fél automatikusan ennek megfelelően csökkenti az kiküldött csomagméreteket. Tehát az MTUPD képes dinamikusan alkalmazkodni a path MTU megváltozásához.
- Hasonlóan, ha a kialakított kapcsolatban növekedik az MTU értéke, akkor az operációs rendszer ezt felismeri, és módosítja a kapcsolat MTU-ját. Ezt az OS úgy éri el, hogy időnként újrapróbálkozik nagyobb méretű ICMP DF csomagokkal. Az újrapróbálás ideje Linux és Windows operációs rendszerek esetében 10 perc.
Sajnálatos módon az MTUPD algoritmus nem mindig működik megfelelően. Ennek az az oka, hogy egyes eszközök letiltják az ICMP csomagok fogadását és/vagy továbbítását. (Általában biztonsági megfontolásokból.) Nem lehet előre megmondani, hogy a két telephelyet összekötő útvonalon van-e (vagy lesz-e a jövőben) olyan eszköz, ami megakadályozza az ICMP csomagok átjutását, és ezzel ellehetetleníti az MTU automatikus meghatározását.
TCP MSS Clamping
A TCP kapcsolatok esetében elterjedt megoldás a fenti probléma kiküszöbölésére a TCP maximális szegmens méret csökkentése vagy más néven MSS Clamping. A TCP MSS csökkentése közvetve csökkenti a TCP csomagok maximális méretét, ezáltal képes csökkenteni a fragmentációt. Ez a következő módon működik. A TCP protokoll a kapcsolat kialakítását az úgynevezett SYN csomagok elküldésével kezdi. Ezek tartalmazzák az egy TCP csomagban elküldhető maximális adat méretet, más néven MSS-t. Amikor egy TCP SYN csomag áthalad egy olyan eszközön, ami tudja magáról hogy nem képes az alapértelmezett 1500 byte -os ethernet frame fragmentálás nélküli továbbítására, akkor módosítja a továbbítandó TCP SYN csomagban található MSS értéket egy alacsonyabb értékre. (Hogy pontosan mi a megfelelő érték, arról később írok). Ezzel a módszerrel TCP kapcsolatok esetén az adott eszközön egész biztosan el lehet kerülni a fragmentációt. Ez a módszer az MTUPD-től teljesen független módon működik, és bármely TCP kapcsolatra alkalmazható.
Az MTU érték magasan tartása növeli a hatékonyságot. Emiatt sok szabályt dolgoztak ki, amivel az overhead-et (header/adat arányt) alacsonyan lehet tartani. Az IPSEC/ESP csomagok overhead-je függ az átviteli módtól (transzport/alagút), a NAT-T beállítástól (kell-e extra UDP header-t beszúrni), a használt titkosítási algoritmustól (például a cipher blokk méretétől) stb. Ráadásul a használt titkosítási algoritmust nem lehet mindig előre rögzíteni. Ha például sok különböző kliens kapcsolódik és különböző proposal-okat használnak, akkor az IKE démon számos különböző algoritmus kombinációt elfogadhat. Ennek bonyolultságával kapcsolatban némi támpontot adhat ez a weblap. Itt látható, hogy például a paddig értéke egy byte-tal kevesebb mint a cipher blokk mérete (legrosszabb eset). Illetve első pillantásra furcsának tűnhet az SHA1 HMAC értékhez beírt 96 bit, de jobban utánanézve kiderül, hogy bizonyos algoritmus kombinációknál nem a teljes HMAC ellenőrző összeget írják be a csomagba, hanem annak csak egy részét. Az utólag hozzáadott újabb típusú algoritmusokra (SHA256+) további RFC-k használhatók. Lehet találni a neten mindenféle MTU kalkulátorokat, azonban ezek nem mindig képesek kiszámítani a megfelelő MTU értéket az általad használt algoritmusokra (feltéve hogy előre ismered őket!), és kétséges a megbízhatóságuk.
Sokkal célravezetőbb az empirikus módszer. Az empirikus módszerhez az szükséges, hogy legyen az alagút mindkét oldalán egy elérhető, ping-elésre képes gép, valamint hogy a ping üzenetek átmenjenek az egyik oldalról a másikra. Windows operációs rendszer alatt erre a a ping parancs a -f és -l kapcsolókkal használható. A -f kapcsoló jelentése: do not fragment. A -l kapcsolóval lehet megadni (növelni) a csomag méretét.
Először egy olyan útvonalon ping-elünk, ahol nincsenek alagutak. Például a branch01 -ben levő Windows10-1 gépről pingeljük az ISP router-ének 10.2.2.2 címét. Kezdetben 1472 byte mérettel próbálkozunk. Az 1472 úgy jön ki, hogy egy ICMP ping csomagban 20 byte IP header és 8 byte ICMP header van. A teljes (alapértelmezett) 1500 byte-os ethernet keretből így 1472 byte marad:
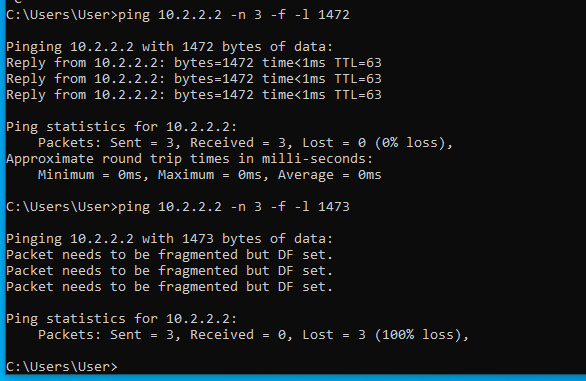
Ahogy látható, az 1472 byte méret átment, az 1473 byte méretre "packet needs to be fragmented but DF set" ICMP hibaüzenetet kaptunk. Ezzel megtudtuk azt, hogy az internet felé menő normál (nem alagutazott) útvonal milyen MTU értékkel rendelkezik. Jelen esetben ez ethernet (layer 2) szinten 1500. Ezután elkezdjük ping-elni az alagút másik oldalán levő valamelyik (bármelyik) gépet egy olyan csomagmérettel, amiről még úgy gondoljuk, hogy fragmentáció nélkül átmegy az alagúton:
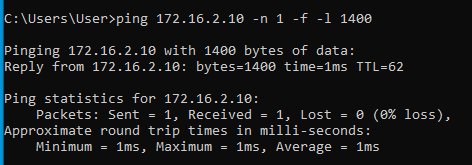
Tehát most már tudjuk, hogy az MTU érték valahol 1472 és 1400 között van. A pontos értéket felező módszerrel viszonylag gyorsan meg tudjuk határozni:
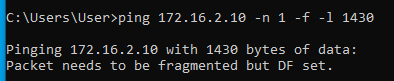
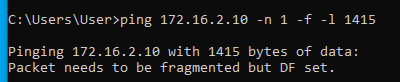

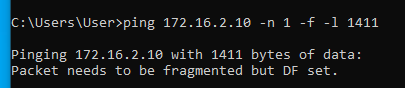
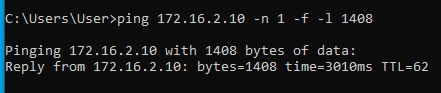


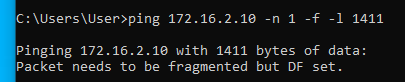
Alagúton legfeljebb 1410 byte adat ment át, alagút nélkül pedig 1472 byte. A kettő között a különbség 1472-1410 = 62 byte. Tehát ennyivel kell csökkenteni az MSS értékét ahhoz, hogy elkerüljük a TCP csomagok fragmentációját.
Egy normál 1500 byte-os TCP/IP csomag felépítése olyan, hogy az IP fejléc elvesz 20 byte-ot, és a TCP fejléc elvesz még 20 byte-ot. Ezért a teljes 1500 byte-os ethernet keretben az MSS értéke nem haladhatja meg az 1460 byte-ot. Az általunk felépített konkrét alagút ennél 62 byte-tal kisebb helyet biztosít. Ezért a fragmentáció nélkül továbbítható legnagyobb MSS érték 1460 - 62 = 1398 byte.
Ezt a számítás egy sorba kiírva:
TCP MSS = 1460 - (1472 - <mért ICMP MTU>) = <mért ICMP MTU> - 12
Mindig az 1472 byte-os alap értékhez viszonyítunk. Ha például az internet kapcsolatod PPPoE-t használ, akkor az első tesztben azt fogod tapasztalni, hogy az ICMP MTU a VPN alagút nélkül 1472 alatt van. Ettől függetlenül a TCP MSS mindig 12 byte-tal kevesebb lesz, mint az általad mért maximuális ICMP ping méret. Ez azért van így, mert a TCP csomag elméleti maximális 1460-as értéke is az 1500 byte-os full ethernet frame-re vonatkozik.
Bár ez a módszer egy kicsit fáradságos, viszont sokkal megbízhatóbban meghatározza a valós MTU értéket, mint egy elméleti számítás.
A fent leírt módszer akkor is célra tud vezetni, ha az útvonalon található router-ek közül valamelyik blokkolja az ICMP üzenetek visszaküldését. Ha a visszajövő ICMP üzenetek blokkolva vannak, akkor az MTUPD biztosan nem működik. Azonban ICMP alapú ping helyett lehet használni UDP vagy TCP alapú pinget. (Erre vannak programok.) Ha nem érkezik vissza válasz a TCP vagy UDP alapú, megnövelt méretű pingre (timeout) akkor ez feltételezhetően azért azért van, mert fragmentáció nélkül nem lehetett átküldeni a csomagot. Tehát a "packet needs to be fragmented but DF set" üzenetet ilyenkor a timeout helyettesítheti (de persze csak akkor, ha van olyan csomagméret, aminél jön vissza ping válasz!)
Ha sokféle algoritmus engedélyezel, és nem vagy biztos abban, hogy az enkapszuláció és az alagutazás pontosan mekkora overhead-et okoz, akkor viszonylag biztonságosan használhatod az 1360 byte-os MSS értéket. Ebbe bőven belefér a NAT-T mód által beszúrt extra 8 byte-os UDP header, és a legerősebb titkosítási algoritmusok overhead-je is. Bár az igaz, hogy ez így nem mindig optimális, de egész biztosan nem okoz fragmentációt. (Annál minden jobb.)
TCP MSS Clamping RouterOS-ben
Tehát olyan szabályt veszünk föl, ami képes lecsökkenteni a TCP SYN csomagok 1360 byte-nál nagyobb MSS értékét 1360-ra. Nagyon fontos hogy olyan szabályt vegyünk föl, ami nem képes növelni az MSS értékét. Ha a csomag már eleve 1360 -nál kisebb MSS értékkel érkezik be, és ezt felülírjuk 1360-ra, akkor ezzel megnöveljük azt, és így végül pont az ellenkezőjét érjük el annak, mint amit szeretnénk (növeljük a fragmentációt ahelyett hogy csökkentenénk).
A megfelelő szabály az office gépen így néz ki:
/ip firewall mangle add action=change-mss chain=forward new-mss=1360 src-address=172.16.1.0/24 protocol=tcp tcp-flags=syn tcp-mss=!0-1360 ipsec-policy=in,ipsec passthrough=yes comment="IKE2: Clamp TCP MSS from 172.16.1.0/24 to ANY"
A branch01 gépen pedig így:
/ip firewall mangle add action=change-mss chain=forward new-mss=1360 src-address=172.16.2.0/24 protocol=tcp tcp-flags=syn tcp-mss=!0-1360 ipsec-policy=in,ipsec passthrough=yes comment="IKE2: Clamp TCP MSS from 172.16.2.0/24 to ANY"
Egy kis magyarázat hozzá:
- Az
src-address,ipsec-policy,protocol=tcpéstcp-flags=synegyüttes használatával kiszűrjük azokat aTCP SYNcsomagokat, amik már átjöttek az alagúton. (Azsrc-addressszűrőben az office router szabályánál ezért szerepel a branch oldal alhálózata.) Ez a szabály így azért jó, mert garantáltan csak azokra a TCP kapcsolatokra módosítja az MSS-t, amik már átjöttek az alagúton. (Azokra nem szeretnénk módosítani, ami nem megy át alagúton!) - A
tcp-mss=!0-1360szabály szó szerint azt jelenti, hogy "a tcp mss értéke nem nulla és 1360 között van". Ez könnyebben értelmezhető formában annyit tesz, hogy nagyobb mint 1360. - A
passthrough=yesazért került oda, mert az MSS megváltoztatása után nem szeretnénk átugrani a többi mangle szabályt. (Bár a jelenlegi példában nincsen több mangle szabály, de ha lennének akkor valószínűleg nem akarnánk átugrani őket.)